

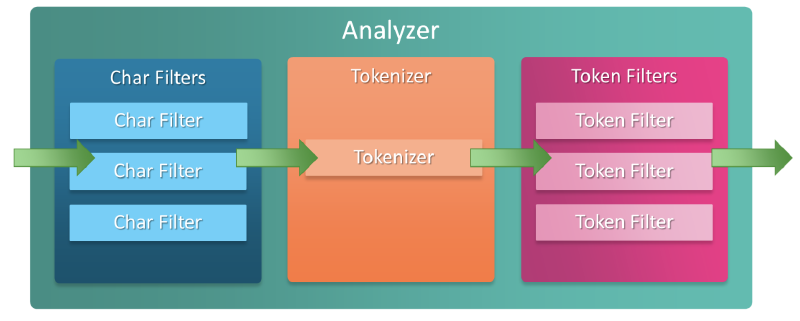
Token Filter#
Token Filter는 Tokenizer에서 생성된 토큰 스트림을 받아 토큰을 추가, 제거 또는 변경하는 역할을 한다.
Word Delimiter Graph Filter#
Word delimiter graph 필터는 제품 ID나 부품 번호와 같은 복잡한 식별자에서 문장 부호를 제거하도록 설계되었다. 이러한 사용 사례의 경우 keyword tokenizer와 함께 사용하는 것이 좋다.
wi-fi와 같은 하이픈으로 연결된 단어를 분리할 때는 word delimiter graph 필터를 사용하지 않는 것이 좋다. 사용자들은 하이픈을 포함하기도 하고 포함하지 않고도 검색을 하기 때문에 synonym graph 필터를 사용하는 것이 좋다.
변환 규칙#
다음과 같은 방식으로 토큰을 분할한다:
- 비영숫자 문자로 토큰 분할:
Super-Duper→Super, Duper - 앞뒤 구분 기호 제거:
XL---42+'Autocoder'→XL, 42, Autocoder - 대소문자 전환 시 분할:
PowerShot→Power, Shot - 문자-숫자 전환 시 분할:
XL500→XL, 500 - 영어 소유격 제거:
Neil's→Neil
API 사용 예시#
GET /_analyze
{
"tokenizer": "keyword",
"filter": ["word_delimiter_graph"],
"text": "Neil's-Super-Duper-XL500--42+AutoCoder"
}
// Result -> [ Neil, Super, Duper, XL, 500, 42, Auto, Coder ]
Custom Analyzer 설정#
PUT /my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "keyword",
"filter": ["word_delimiter_graph"]
}
}
}
}
}
Configurable Parameters#
adjust_offsets#
- Default:
true - true일 경우 필터는 토큰 스트림에서 실제 위치를 더 잘 반영하도록 분할 토큰 또는 체이닝된 토큰의 시작점을 조정함
- 만약 trim 같은 필터를 사용한다면 offset의 변화 없이 token의 길이를 변경하기 때문에 함께 사용할 때는
false로 해야 함
catenate_all#
- Default:
false - true이면 필터는 영숫자가 아닌 구분 기호로 구분된 영숫자 체인에 대해 체이닝 토큰을 생성함
- 예시:
super-duper-xl-500→[ superduperxl500, super, duper, xl, 500 ]
catenate_numbers#
- Default:
false - true이면 필터는 알파벳이 아닌 구분 기호로 구분된 숫자 문자 체인에 대해 카테네이트 토큰을 생성함
- 예시:
01-02-03→[ 010203, 01, 02, 03 ]
catenate_words#
- Default:
false - true이면 필터는 알파벳이 아닌 구분 기호로 구분된 알파벳 문자 체인에 대해 카테네이트 토큰을 생성함
- 예시:
super-duper-xl→[ superduperxl, super, duper, xl ]
⚠️ Catenate 파라미터 사용 시 주의점
이 매개변수를 true로 설정하면 인덱싱에서 지원되지 않는 다중 위치 토큰이 생성함
이 매개변수가 true이면 인덱스 분석기에서 이 필터를 사용하지 않거나 이 필터 뒤에 flatten_graph 필터를 사용하여 토큰 스트림을 인덱싱에 적합하게 만들어야함
검색 분석에 사용할 경우, 카테네이트된 토큰은 match_phrase 쿼리 및 일치하는 토큰 위치에 의존하는 다른 쿼리에 문제를 일으킬 수 있음. 이러한 쿼리를 사용하려는 경우 이 매개변수를 true로 설정하지 않아야 함.
generate_number_parts#
- Default:
true - true이면 필터는 출력에 숫자로 구성된 토큰을 포함함
- false인 경우 필터는 이러한 토큰을 출력에서 제외함
generate_word_parts#
- Default:
true - true이면 필터는 출력에 알파벳 문자로 구성된 토큰을 포함함
- false일 경우 이러한 토큰을 출력에서 제외함
ignore_keywords#
- Default:
false - true일 경우 필터는 키워드 속성이 true인 토큰을 건너뜀
preserve_original#
- Default:
false - true이면 필터는 출력에 분할된 토큰의 원본 버전을 포함함
- 이 원본 버전에는 영숫자가 아닌 구분 기호가 포함됨
- 예시:
super-duper-xl-500→[ super-duper-xl-500, super, duper, xl, 500 ]
⚠️ preserve_original 파라미터 사용 시 주의점
이 매개변수를 true로 설정하면 인덱싱에서 지원되지 않는 다중 위치 토큰이 생성함
이 매개변수가 true이면 인덱스 분석기에서 이 필터를 사용하지 않거나 이 필터 뒤에 flatten_graph 필터를 사용하여 토큰 스트림을 인덱싱에 적합하게 만들어야함
protected_words#
(Optional, array of strings)
- 필터가 분할하지 않는 토큰의 배열
protected_words_path#
(Optional, string)
- 필터가 분할하지 않는 토큰 목록이 포함된 파일의 경로
- 이 경로는 구성 위치에 대한 절대 경로이거나 상대 경로여야 하며, 파일은 UTF-8로 인코딩되어야 함
- 파일의 각 토큰은 줄 바꿈으로 구분해야 함
split_on_case_change#
(Optional, Boolean)
- Default:
true - true이면 필터는 대소문자 전환 시 토큰을 분할함
- 예시:
camelCase→[ camel, Case ]
split_on_numerics#
(Optional, Boolean)
- Default:
true - true이면 필터는 문자-숫자 전환 시 토큰을 분할함
- 예시:
j2se→[ j, 2, se ]
stem_english_possessive#
(Optional, Boolean)
- Default:
true - true이면 필터는 각 토큰의 끝에서 영어 소유격(’s)을 제거함
- 예시:
O'Neil's→[ O, Neil ]
type_table#
(Optional, array of strings)
- 문자에 대한 사용자 지정 유형 매핑의 배열
- 이를 통해 영숫자가 아닌 문자를 숫자 또는 영숫자로 매핑하여 해당 문자의 분할을 방지할 수 있음
예시
[ "+ => ALPHA", "- => ALPHA" ]
위 배열은 더하기(+) 및 하이픈(-) 문자를 영숫자로 매핑하므로 구분 기호로 취급되지 않음.
지원되는 타입
ALPHA(Alphabetical)ALPHANUM(Alphanumeric)DIGIT(Numeric)LOWER(Lowercase alphabetical)SUBWORD_DELIM(Non-alphanumeric delimiter)UPPER(Uppercase alphabetical)
type_table_path#
(Optional, string)
- custom type mapping 파일 경로
작성 예시
# Map the $, %, '.', and ',' characters to DIGIT
# This might be useful for financial data.
$ => DIGIT
% => DIGIT
. => DIGIT
\u002C => DIGIT
# in some cases you might not want to split on ZWJ
# this also tests the case where we need a bigger byte[]
# see https://en.wikipedia.org/wiki/Zero-width_joiner
\u200D => ALPHANUM
이 파일 경로는 설정 위치에 대한 절대 경로이거나 상대 경로여야 하며, 파일은 UTF-8로 인코딩되어야 함. 파일의 각 매핑은 줄 바꿈으로 구분함.
사용 시 주의사항#
Standard tokenizer와 같이 구두점을 제거하는 토큰화기와 함께 word_delimiter_graph 필터를 사용하지 않는 것이 좋다. 이렇게 하면 word_delimiter_graph 필터가 토큰을 올바르게 분할하지 못할 수 있다.
또한 catenate_all 또는 preserve_original과 같은 필터의 구성 가능한 매개변수를 방해할 수도 있다. 대신 keyword 또는 whitespace tokenizer를 사용하는 것이 좋다.


