

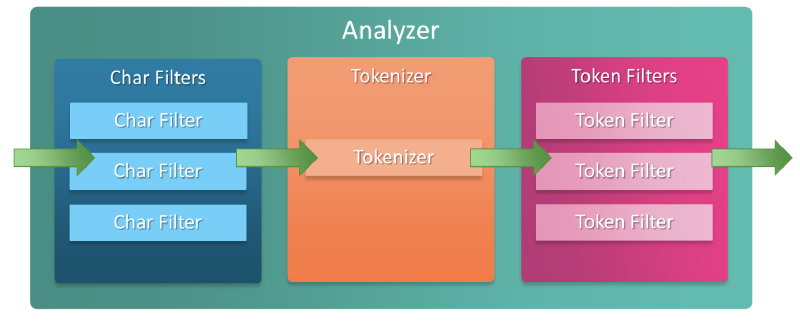
Tokenizer#
Tokenizer는 문자열 스트림을 받고 각각의 토큰 단위로 자른다. (주로 각각의 단어별로 토큰화가 이루어짐)
가장 standard하게 사용되는 whitespace tokenizer는 공백을 기준으로 잘라 토큰화를 진행한다.
Whitespace Tokenizer 예시#
// character streams
Quick brown fox!
// Result
[Quick, brown, fox!]
Tokenizer의 책임#
- 각 용어의 정렬과 포지션 (구 또는 단어 유사성 쿼리에서 사용)
- 변형 전의 기존 단어의 시작과 끝 문자는 검색 스니펫 하이라이팅에 사용됨
- Token별 타입:
<ALPHANUM>,<HANGUL>,<NUM>등 (단순한 analyzer는 오직 단어 토큰 타입만 제공함)
Word Oriented Tokenizer#
아래 tokenizer들은 풀 텍스트에서 각각의 단어로 토큰화를 하는데 사용된다.
Standard Tokenizer#
standard tokenizer는 Unicode Text Segmentation algorithm을 기반으로 토큰화를 진행한다.
Configuration#
max_token_length: 지정된 길이를 초과하는 문자열을 기점으로 잘라 토큰화를 진행- Default = 255
변환 예시#
POST _analyze
{
"tokenizer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// Result -> [ The, 2, QUICK, Brown, Foxes, jumped, over, the, lazy, dog's, bone ]
max_token_length 적용 예시#
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "standard",
"max_token_length": 5
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// Result -> [ The, 2, QUICK, Brown, Foxes, jumpe, d, over, the, lazy, dog's, bone ]
Letter Tokenizer#
letter tokenizer는 문자열이 아닌 것을 기점으로 잘라 토큰화를 진행한다. 이는 유럽권 언어(영미권)에는 적합하나 아시아 언어, 특히 공백을 기점으로 단어가 나뉘지 않는 언어에는 적합하지 않다.
변환 예시#
POST _analyze
{
"tokenizer": "letter",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// Result -> [ The, QUICK, Brown, Foxes, jumped, over, the, lazy, dog, s, bone ]
Lowercase Tokenizer#
lowercase tokenizer는 letter tokenizer처럼 문자열이 아닌 것을 기점으로 잘라 토큰화를 진행하며, 추가적으로 모든 문자열을 소문자로 변환한다. 기능적으로는 letter tokenizer와 동일하면서도 소문자로 변환하는 기능을 한번에 수행함으로 효율적이다.
변환 예시#
POST _analyze
{
"tokenizer": "lowercase",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// Result -> [ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ]
Whitespace Tokenizer#
whitespace tokenizer는 공백 문자열을 기준으로 토큰화를 진행한다.
Configuration#
max_token_length: 지정된 길이를 초과하는 문자열을 기점으로 잘라 토큰화를 진행- Default = 255
변환 예시#
POST _analyze
{
"tokenizer": "whitespace",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// Result -> [ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog's, bone. ]
UAX URL Email Tokenizer#
uax_url_email tokenizer는 standard tokenizer와 동일하지만, 한 가지 다른점은 URLs이나 email 주소를 인식하고 하나의 토큰으로 취급을 한다.
Configuration#
max_token_length: 지정된 길이를 초과하는 문자열을 기점으로 잘라 토큰화를 진행- Default = 255
변환 예시#
POST _analyze
{
"tokenizer": "uax_url_email",
"text": "Email me at john.smith@global-international.com"
}
// Result -> [ Email, me, at, john.smith@global-international.com ]
// 위의 예시를 만약 standard tokenizer로 한다면 다음과 같은 결과가 나옴
// Result -> [ Email, me, at, john.smith, global, international.com ]
Configuration 예시#
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "uax_url_email",
"max_token_length": 5
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "john.smith@global-international.com"
}
// Result (email 형식을 무시하고 max_token_length가 우선순위가 됨)
// [ john, smith, globa, l, inter, natio, nal.c, om ]
Classic Tokenizer#
classic tokenizer는 문법 베이스의 토큰화를 진행하고 영어 document에 좋다. 이 토큰화 방식은 약어, 회사 이름, 이메일 주소, 인터넷 호스트 이름을 특별하게 처리하는 방식이 있다. 그러나 이러한 규칙들이 항상 동작하지는 않고, 영어 이외의 언어에서는 잘 동작하지 않는다.
Tokenizing 규칙#
- 대부분 구두점을 기준으로, 구두점을 제거하며 단어를 나눈다. 하지만 공백이 뒤따르지 않는 점은 토큰의 일부로 간주된다.
- 하이픈을 기준으로 단어를 나누긴 하지만 만약 해당 단어에 하이픈이 있을 경우 제품번호로 인식을 하고 나누지 않는다. (예: 123-23)
- email과 internet hostname은 하나의 토큰으로 간주한다.
Configuration#
max_token_length: 지정된 길이를 초과하는 문자열을 기점으로 잘라 토큰화를 진행- Default = 255
변환 예시#
POST _analyze
{
"tokenizer": "classic",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
// Result -> [ The, 2, QUICK, Brown, Foxes, jumped, over, the, lazy, dog's, bone ]
Thai Tokenizer#
thai tokenizer는 태국어 텍스트를 단어 단위로 토큰화를 시킨다. Java에 포함되어 있는 Thai segmentation algorithm을 사용한다. 만약 input text에 태국어가 아닌 다른 언어의 문자열이 함께 포함되어 있는 경우는 해당 문자열에 한해 standard tokenizer가 적용된다.
⚠️ 주의사항: 해당 토큰화 방식은 일부 JRE에서 지원되지 않을 수 있음. 이 토큰화 방식은 Sun/Oracle 및 OpenJDK에서 작동하는 것으로 알려져 있음. 어플리케이션에 완전한 이식성을 고려하는 경우 ICU tokenizer를 대신 사용하는 것을 고려하는 것이 좋음
변환 예시#
POST _analyze
{
"tokenizer": "thai",
"text": "การที่ได้ต้องแสดงว่างานดี"
}
// Result -> [ การ, ที่, ได้, ต้อง, แสดง, ว่า, งาน, ดี ]

