

Elastic Search 는 Apache Lucene 기반의 Java 오픈소스 분산 검색 엔진이다.
ElasticSearch 를 통해 루씬 라이브러리(Java에서 개발한 정보 검색용 라이브러리)를 단독으로 사용할 수 있으며, 방대한 양의 데이터를 실시간에 가깝게 저장, 검색, 분석을 수행할 수 있다.
ElasticeSearch 는 검색을 위해 단독으로 사용되기도 하며, ELK(Elasticsearch / Logstash / Kibana) 스택으로 사용되기도 한다.
ELK 스택 구성 요소#
- Elasticsearch: Logstash로 부터 받은 데이터를 검색 및 집계하여 필요한 정보를 획득
- Logstash: 다양한 소스(DB, csv 파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달
- Kibana: Elasticsearch 의 빠른 검색을 통해 데이터를 시각화 및 모니터링
💡 주로 ELK는 로드밸런싱되어 있는 WAS의 흩어져있는 로그를 한 곳으로 모으고, 원하는 데이터를 빠르게 검색한 뒤 시각화하여 모니터링하기 위해 사용한다.
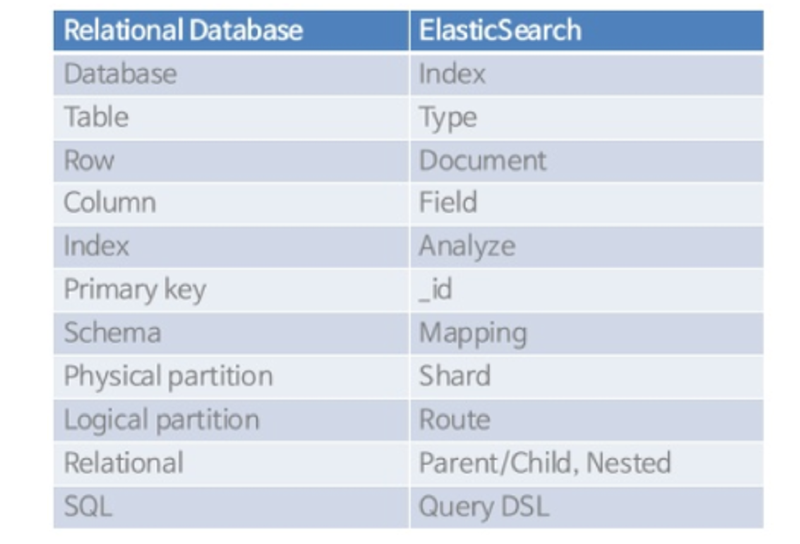
Elasticsearch 와 RDB 의 명칭 비교#

Elasticsearch 7.0 부터는 하나의 인덱스에 하나의 타입만 가질 수 있음#
이 이유는 Elasticsearch는 하나의 인덱스(DB) 안에서의 타입은 같은 Lucene 필드를 사용한다. 따라서 타입은 다를지라도 동일한 이름을 가진 필드는 독립적이지 않아으므로 여러가지 문제가 발생할 수 있으므로 하나의 인덱스는 하나의 타입만을 갖도록 수정이 되었다.
RDB와의 비교#
RDB의 경우
- 하나의 DB에 여러 테이블이 있고 각 테이블에 동일한 이름의 컬럼이 존재해도 서로 영향을 미치지 않는다.
Elasticsearch의 경우
- 하나의 인덱스(=DB) 내의 각 타입(=테이블)에 동일한 이름을 가진 필드(=컬럼)가 있을 경우, 해당 필드는 독립적이지 않고 동일한 Lucene 필드에 저장되며 동일한 정의를 가져야 한다.
Elasticsearch 구조#

클러스터 (Cluster)#
클러스터란 Elasticsearch 에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드의 집합이다.
- 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지됨
- 여러 대의 서버가 하나의 클러스터를 구성할 수 있음
- 한 서버에 여러 개의 클러스터가 존재할 수 있음
노드 (Node)#
노드는 클러스터에 포함된 단일 서버로서 데이터를 저장하고 클러스터의 색인화 및 검색 기능에 참여한다. 노드는 역할에 따라 다음과 같이 구분한다.
Master-eligible Node#
클러스터를 제어하는 마스터로 선택할 수 있는 노드
- 인덱스 생성, 삭제
- 클러스터 노드의 추적 관리
- 데이터 입력 시 할당할 샤드 선택
Data Node#
데이터(Document)가 저장되는 노드이며, 데이터가 분산 저장되는 공간인 샤드가 배치되는 노드
- CRUD, 색인, 검색, 통계 등의 데이터 작업을 수행
- 많은 리소스(CPU, 메모리 등)를 필요로 함
- 모니터링 작업이 필요하며, 마스터 노드와는 분리해야 함
Ingest Node#
데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할
Coordination Only Node#
사용자의 요청을 받고 라운드 로빈 방식으로 분산하는 노드
- 클러스터에 관련된 것은 마스터 노드로 전달
- 데이터와 관련된 것은 데이터 노드로 전달
- 로드밸런싱 역할을 수행
인덱스 / 샤드 / 복제#
인덱스 (Index)#
RDB의 데이터베이스와 대응하는 개념
샤드 (Shard)#
인덱스 내부에 색인된 데이터들이 하나로 뭉쳐서 존재하지 않고 여러 부분으로 나뉘어 존재함. 스케일 아웃을 위해 하나의 인덱스를 여러 샤드로 쪼갬.
💡 샤드는 프라이머리 샤드와 레플리카 샤드로 나뉜다.
프라이머리 샤드 (Primary Shard)
- 데이터의 원본
- 데이터 업데이트 요청은 프라이머리 샤드에 전달됨
- 업데이트된 내용은 레플리카 샤드에 복제됨
레플리카 샤드 (Replica Shard)
- 프라이머리 샤드의 복제본
- 원본 데이터가 손실되었을 때 대신 사용하면서 장애를 극복하는 역할을 수행
- 기본적으로 원본인 프라이머리 샤드와 다른 노드에 배정됨
세그먼트 (Segment)#
세그먼트는 ElasticSearch 에서 문서의 빠른 검색을 위해 설계된 자료 구조이며, 샤드의 데이터를 가지고 있는 물리적인 파일이다.
세그먼트의 특징#
- 각 샤드는 다수의 세그먼트로 구성되어 있어 검색 요청을 분산 처리하여 효율적인 검색이 가능
- 샤드에서 검색 시, 먼저 각 세그먼트를 검색하여 결과를 조합한 후 최종 결과를 해당 샤드의 결과로 반환
- 세그먼트 내부에 색인된 데이터가 역색인 구조로 저장되어 있어 검색 속도가 매우 빠름
세그먼트 생성 과정#
매 요청마다 새로운 세그먼트를 만들면 너무 많은 세그먼트가 생성되므로 이를 방지하기 위해 인메모리 버퍼를 사용한다.
Flush: 인메모리 버퍼에 쌓인 내용이 일정 시간이 지나거나 버퍼가 가득 차면 flush를 수행하고, 시스템 캐시에 세그먼트가 생성됨
- 이 시점부터 데이터 검색이 가능
- 이 상태는 세그먼트가 시스템 캐시에 저장된 상태이지 디스크에 저장된 상태가 아님
Commit: 일정 시간이 지나면 commit을 통해 물리적인 디스크에 세그먼트를 저장
병합: 저장된 세그먼트는 시간이 지날수록 하나로 병합하는 과정을 수행
- 병합을 통해 세그먼트를 하나로 줄여주면 검색할 세그먼트 개수가 줄어 검색 성능이 향상됨