

Clustering#
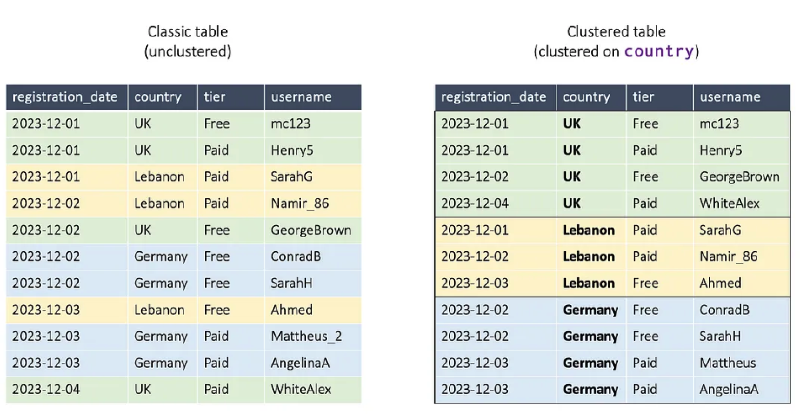
SELECT *
FROM user_signups
WHERE
country = 'Lebanon'
AND registration_date = '2023-12-01'
Clustering을 통해 BigQuery가 데이터 접근에 있어 더 적은 일을 수행하게 하여 Query 속도를 올릴 수 있음. 하지만 Clustering을 하기 전에 테이블의 데이터 양을 생각하여 클러스터링을 처리하는 비용이 더 안 좋을 수 있을지를 생각하는 것이 좋음.
예를 들어 BigQuery의 column based 테이블이 10 rows밖에 데이터가 없다고 생각을 하면 clustering을 하는 비용이 데이터를 풀스캔하는 비용보다 더 많이 나올 것임을 인지해야 함.
전 구글 엔지니어의 말을 인용하면 클러스터링을 하기 위한 데이터 그룹당 100MB 미만이라면 클러스터링을 하는 것보다 풀스캔을 하는 것이 더 나을 수 있다고 함.
중요 사항
추가적으로 클러스터링을 한 base 컬럼을 query 시에 필터링하지 않으면 아무런 query performance에 아무런 도움이 되지 않음.
Example of Creating Clustered Tables#
CREATE TABLE `myproject.mydataset.clustered_table` (
registration_date DATE,
country STRING,
tier STRING,
username STRING
) CLUSTER BY country;
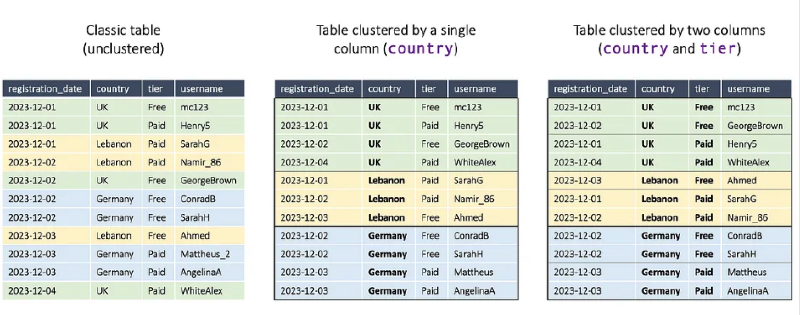
Clustering 특징
- 최대 4개의 column까지 클러스터링 가능
- Partitioning과 다르게 INT64, DATE 타입만 사용할 수 있지 않음
- STRING과 GEOGRAPHY와 같은 타입도 사용 가능
Combine Clustering with Partitioning#
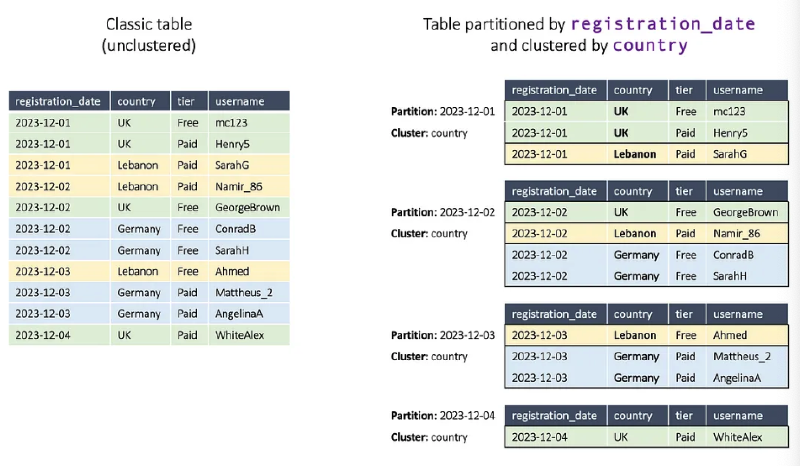
파티셔닝과 클러스터링을 함께 사용하면 더욱 효율적인 데이터 접근이 가능함.
조합 전략
- Partitioning: 날짜 기반 데이터 분할
- Clustering: 파티션 내부에서 추가적인 정렬
- 쿼리 성능과 비용 최적화



